1. 13.4 Boosting
1.1. 学习目标
- 知道boosting集成原理和实现过程
- 知道bagging和boosting集成的区别
- 知道AdaBoost集成原理
1.2. 1 什么是boosting

随着学习的积累从弱到强
简而言之:每新加入一个弱学习器,整体能力就会得到提升
代表算法:Adaboost,GBDT,XGBoost,LightGBM
1.3. 2 实现过程:
1.训练第一个学习器
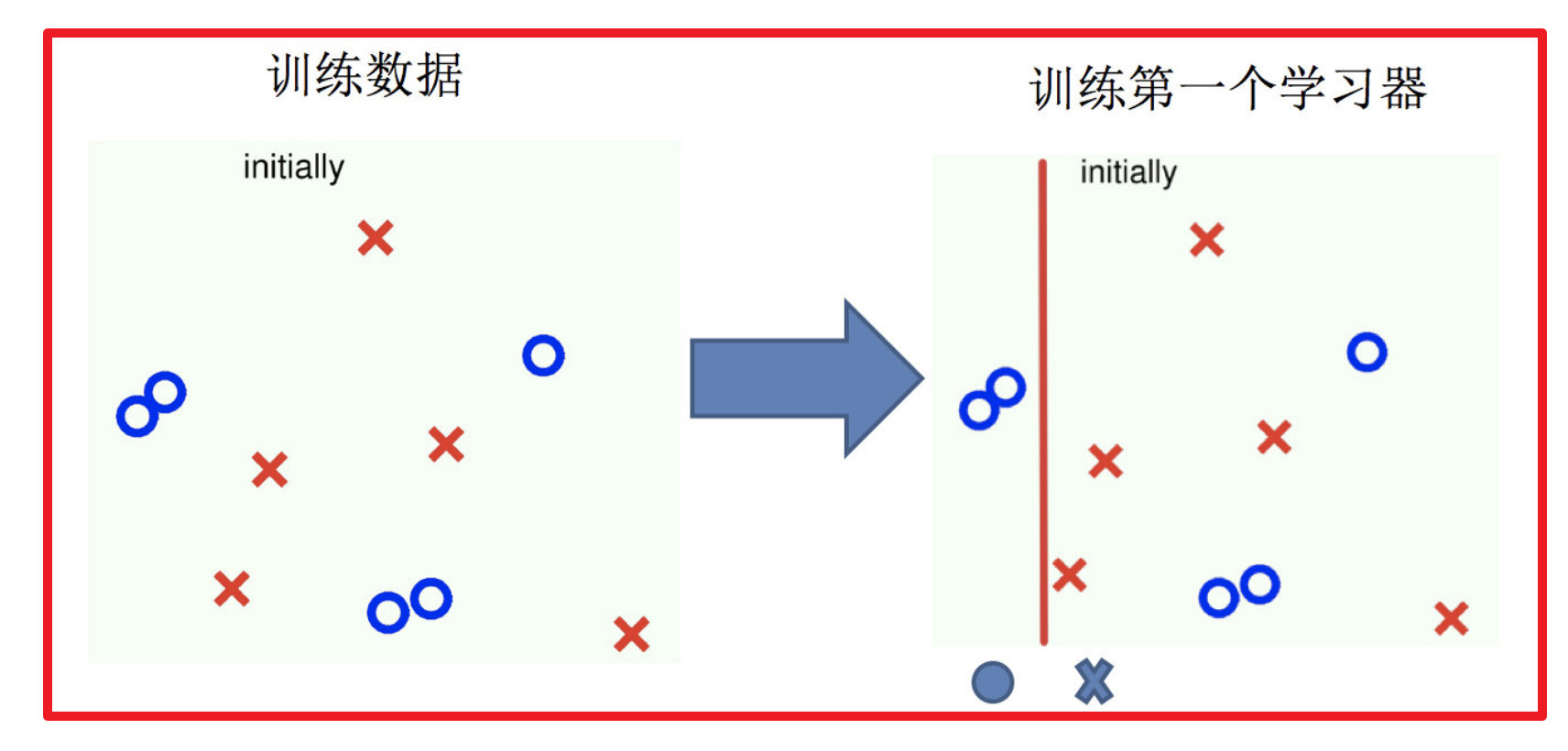
2.调整数据分布
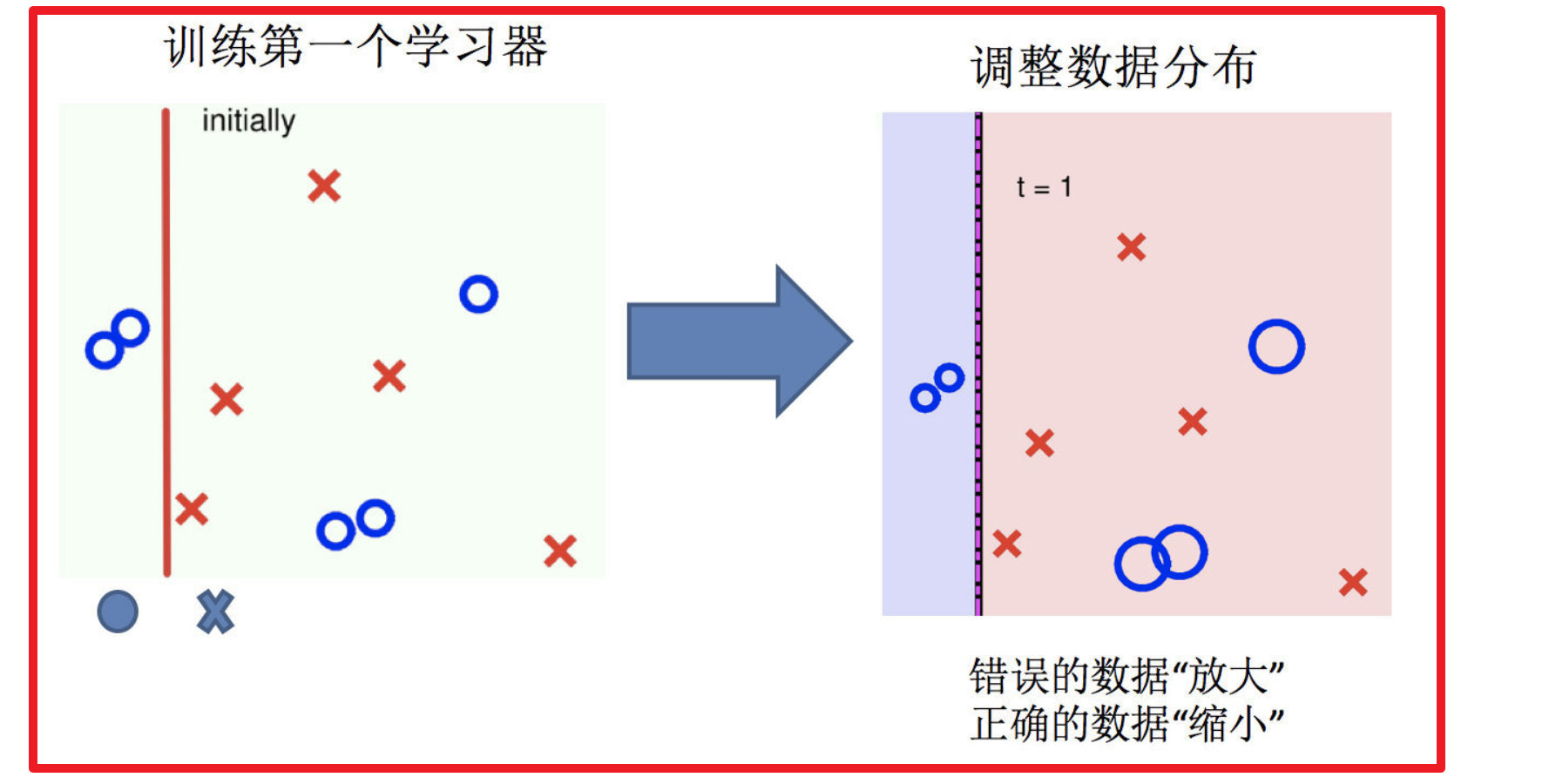
3.训练第二个学习器
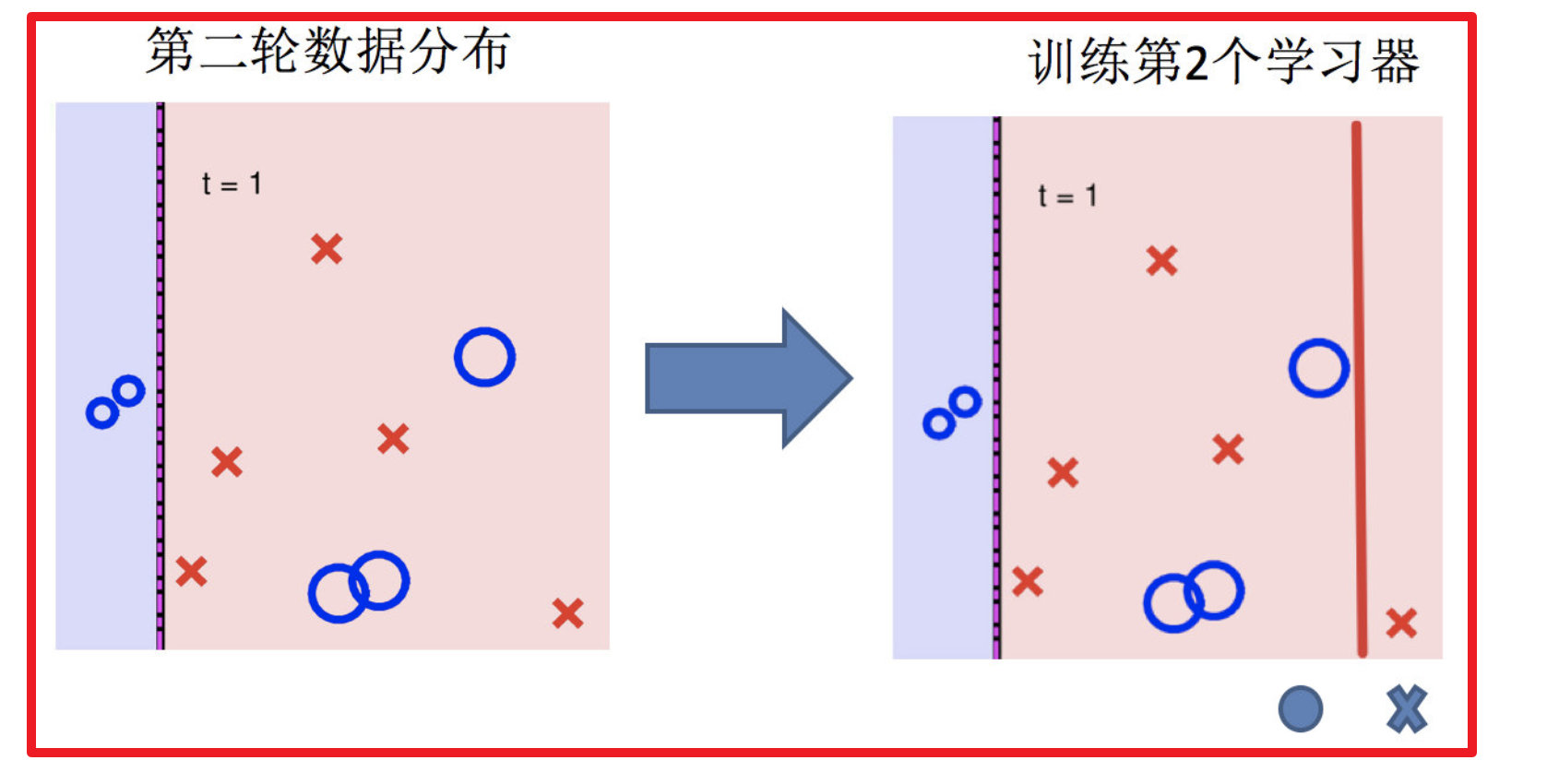
4.再次调整数据分布
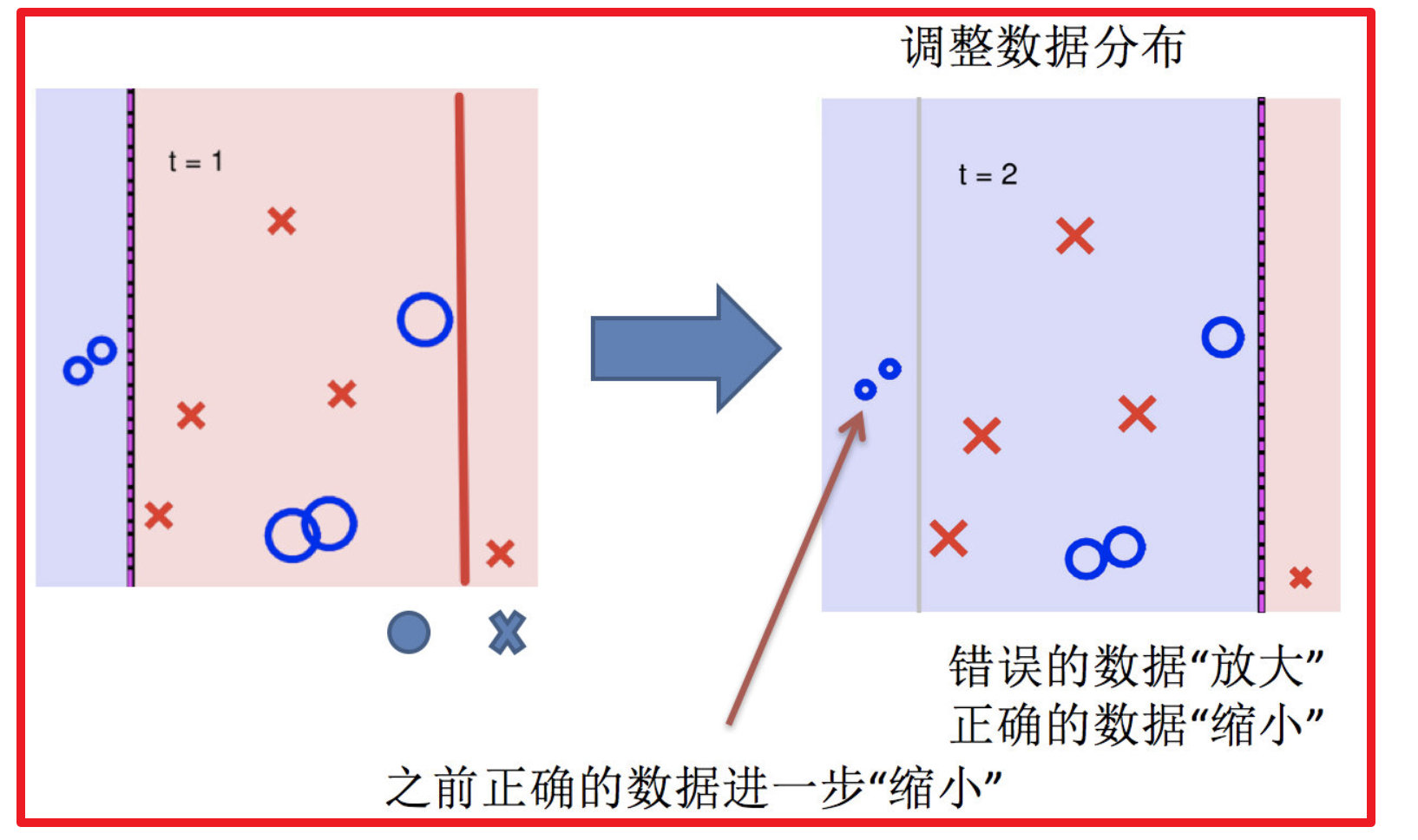
5.依次训练学习器,调整数据分布
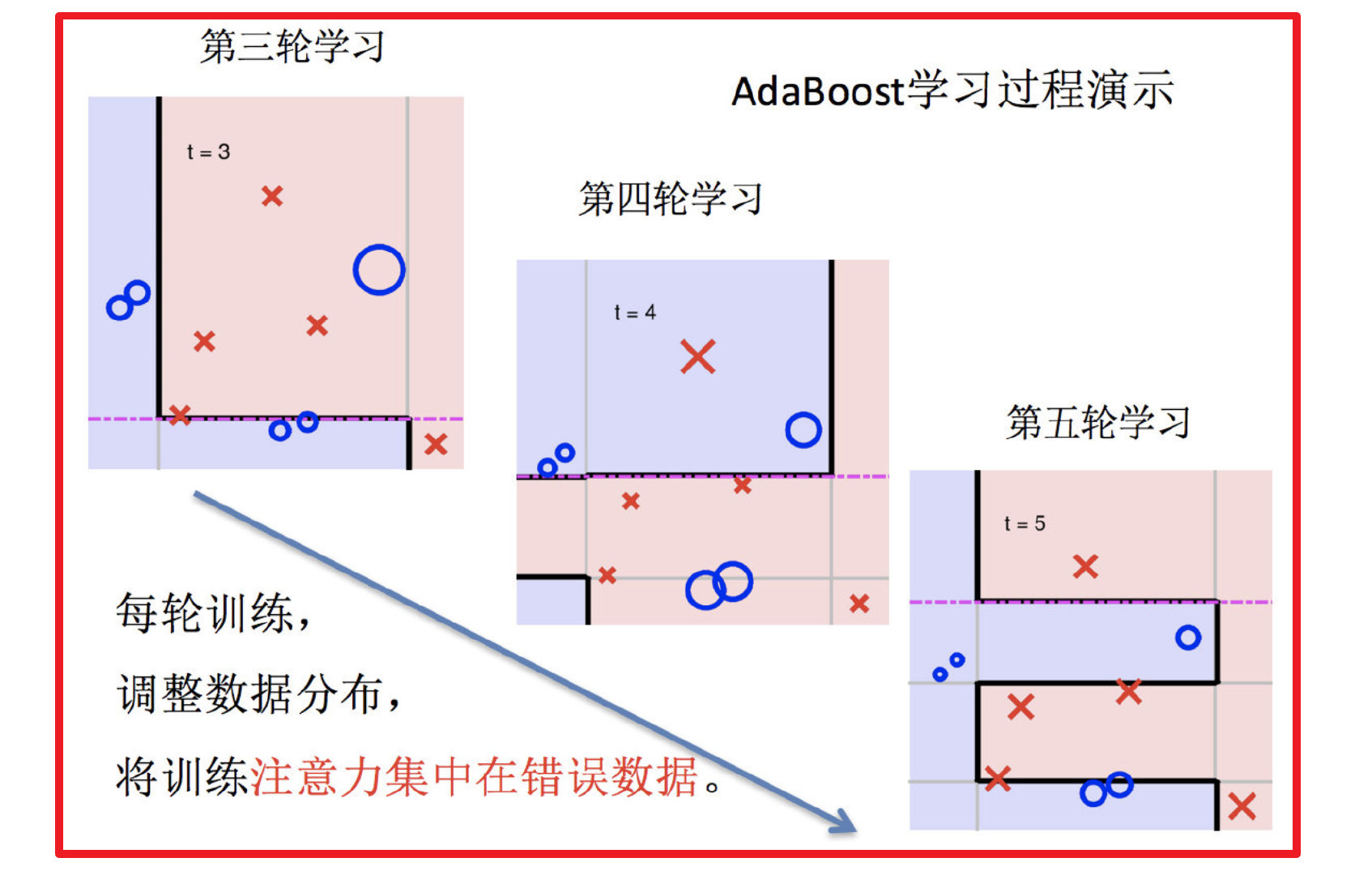
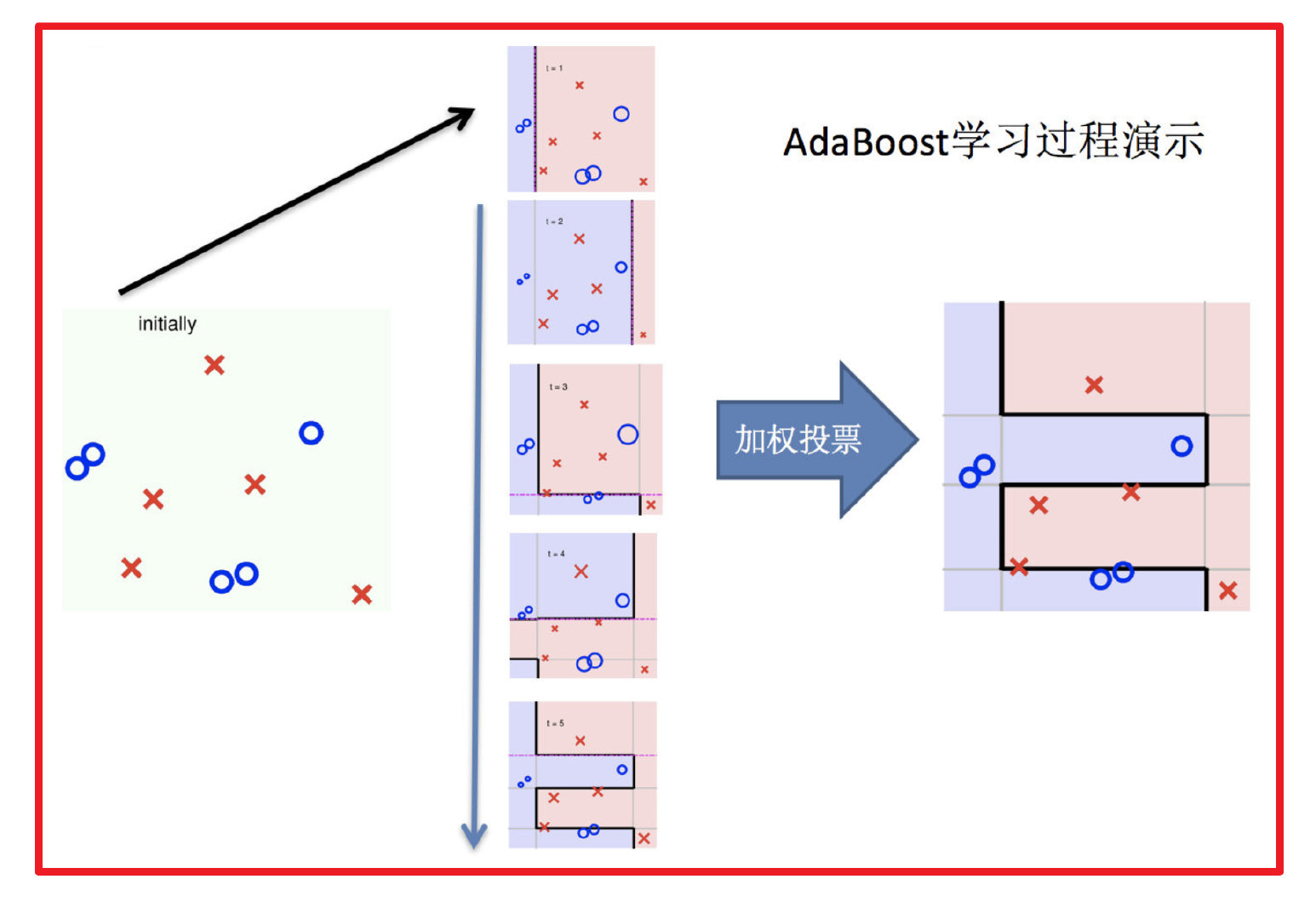
6.整体过程实现
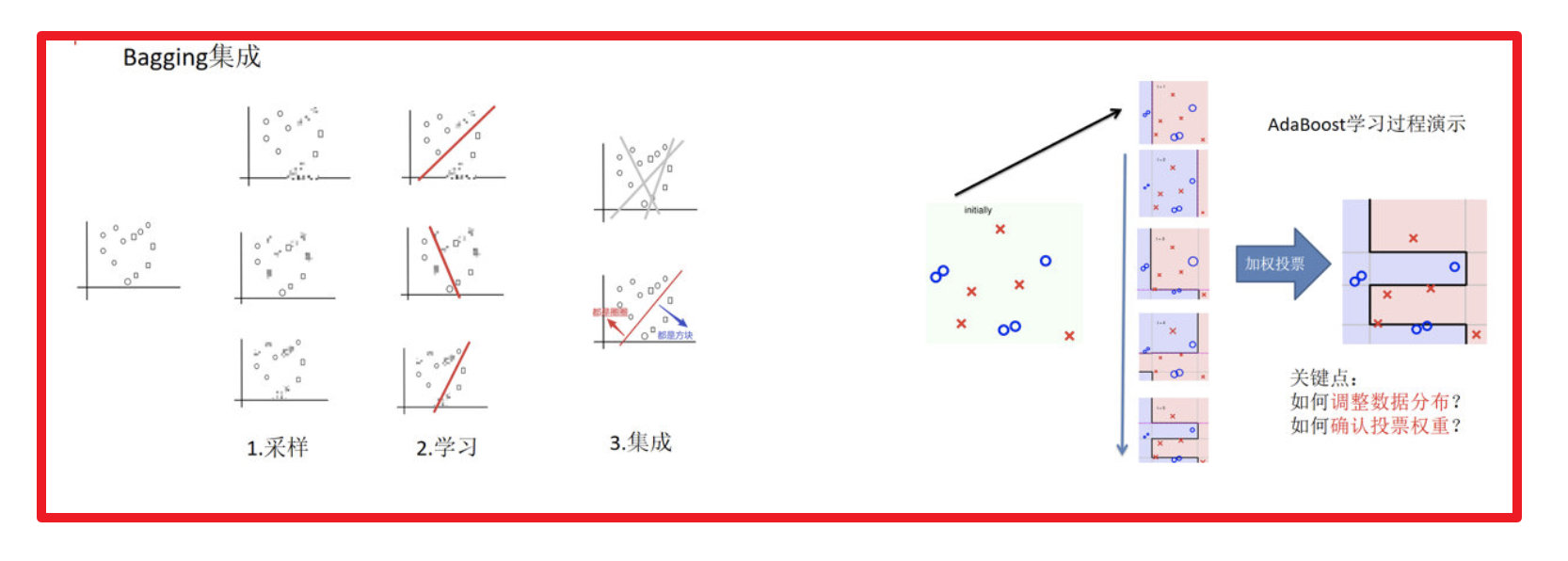
1.4. 3 bagging与boosting的区别
- 区别一:数据方面
- Bagging:对数据进行采样训练;
- Boosting:根据前一轮学习结果调整数据的重要性。
- 区别二:投票方面
- Bagging:所有学习器平权投票;
- Boosting:对学习器进行加权投票。
- 区别三:学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
- Boosting学习是串行,学习有先后顺序。
- 区别四:主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
- Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
1.5. 4 AdaBoost介绍
1.5.1. 4.1 构造过程细节
步骤一:初始化训练数据权重相等,训练第一个学习器。
该假设每个训练样本在基分类器的学习中作用相同,这一假设可以保证第一步能够在原始数据上学习基本分类器H1(x)
步骤二:AdaBoost反复学习基本分类器,在每一轮m=1,2,...,M 顺次的执行下列操作:
(a) 在权值分布为Dt的训练数据上,确定基分类器;
(b) 计算该学习器在训练数据中的错误率:
εt=P(ht(xt)≠yt)
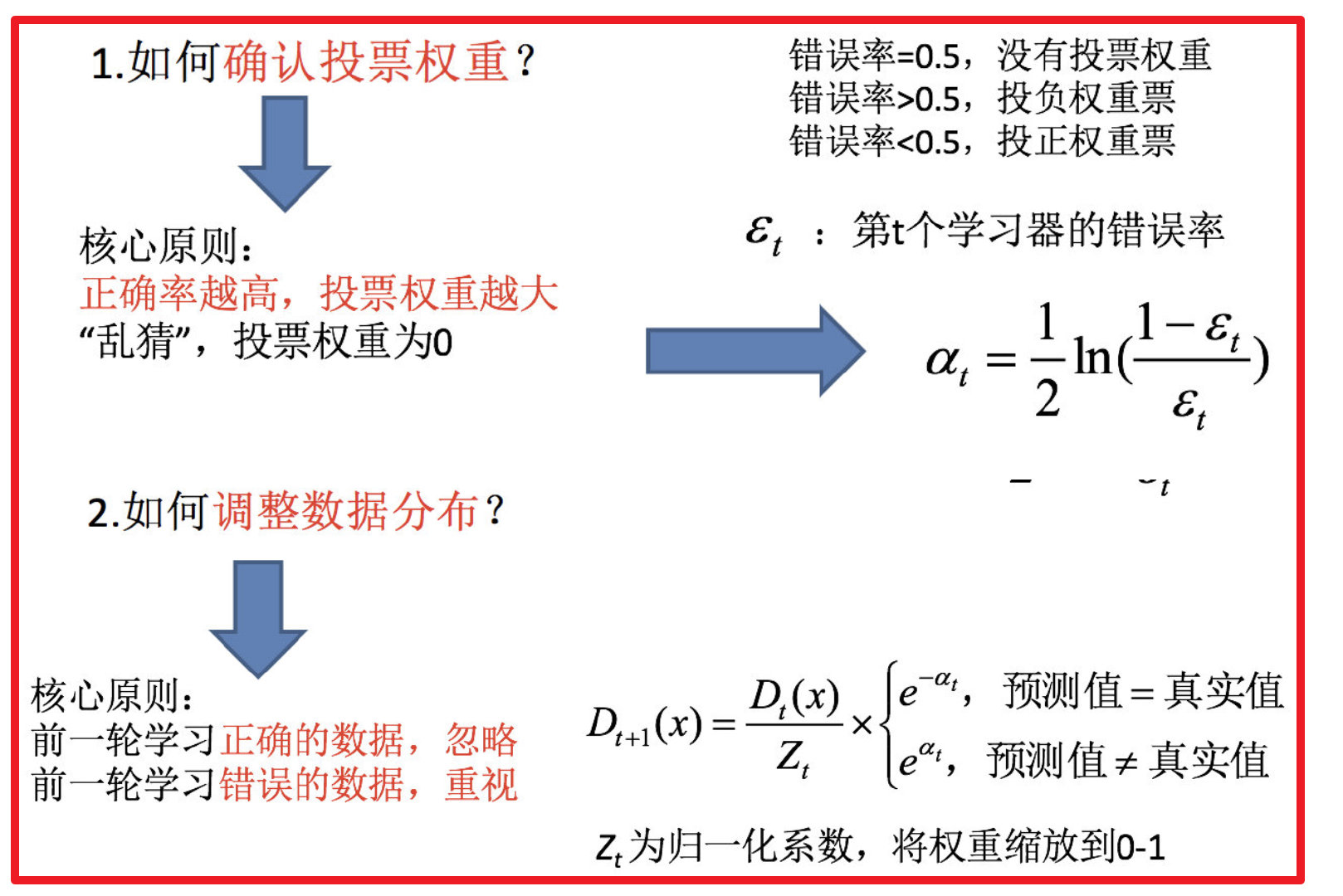
(c) 计算该学习器的投票权重:
αt=21ln(εt1−εt)
(d) 根据投票权重,对训练数据重新赋权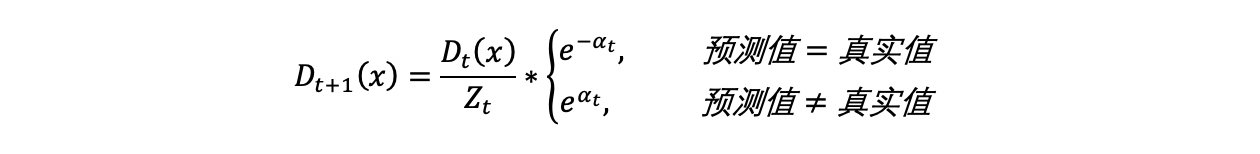
重复执行a到d步,m次;
步骤三:对m个学习器进行加权投票
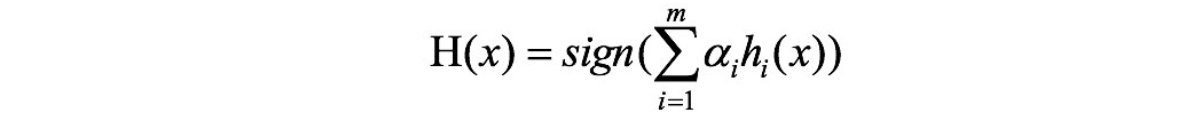
1.5.2. 4.2 关键点剖析
如何确认投票权重?
如何调整数据分布?
1.5.3. 4.3 案例介绍
给定下面这张训练数据表所示的数据,假设弱分类器由xv产生,其阈值v使该分类器在训练数据集上的分类误差率最低,试用Adaboost算法学习一个强分类器。

问题解答:
步骤一:初始化训练数据权重相等,训练第一个学习器:
D1=(w11,w12,...,w110,)
w1i=0.1,i=1,2,...,10
步骤二:AdaBoost反复学习基本分类器,在每一轮m=1,2,...,M顺次的执行下列操作:
当m=1的时候:
(a)在权值分布为D1的训练数据上,阈值v取2.5时分类误差率最低,故基本分类器为:
6,7,8被分错
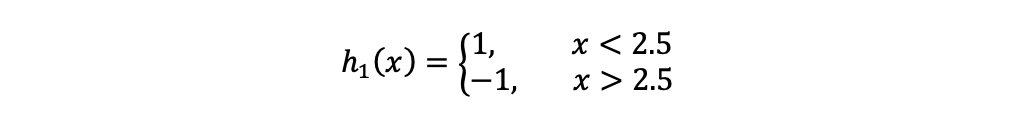
(b)计算该学习器在训练数据中的错误率:
ε1=P(h1(x1)≠y1)=0.3
(c)计算该学习器的投票权重:
α1=21ln(ε11−ε1)=0.4236
(d)根据投票权重,对训练数据重新赋权:
D2=(w21,w22,...,w210,)
根据下公式,计算各个权重值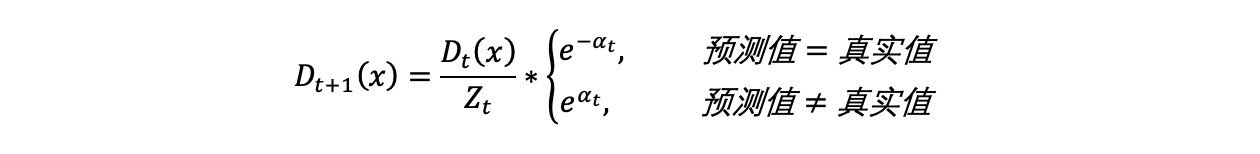
经计算得,D2的值为:
D2=(0.07143,0.07143,0.07143,0.07143,0.07143,0.07143,0.16667,0.16667,0.16667,0.07143)
计算过程:
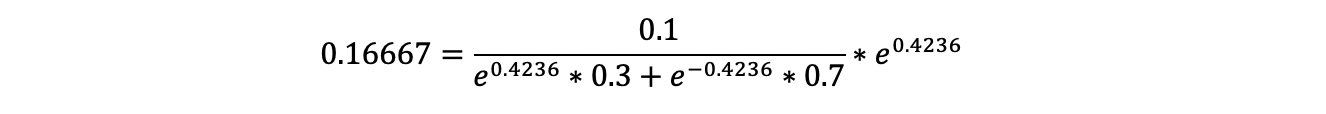
H1(x)=sign[0.4236h1(x)]
分类器H1(x)在训练数据集上有3个误分类点。
当m=2的时候:
(a)在权值分布为D2的训练数据上,阈值v取8.5时分类误差率最低,故基本分类器为:
3,4,5被分错
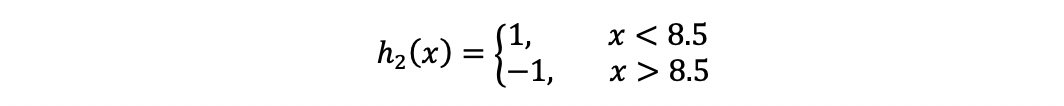
(b)计算该学习器在训练数据中的错误率:
ε2=P(h2(x2)≠y2)=0.2143
(c)计算该学习器的投票权重:
α2=21ln(ε21−ε2)=0.6496
(d)根据投票权重,对训练数据重新赋权:
经计算得,D3的值为:
D3=(0.0455,0.0455,0.0455,0.1667,0.1667,0.1667,0.1060,0.1060,0.1060,0.0455)
H2(x)=sign[0.4236h1(x)+0.6496h2(x)]
分类器H2(x)在训练数据集上有3个误分类点。
当m=3的时候:
(a)在权值分布为D3的训练数据上,阈值v取5.5时分类误差率最低,故基本分类器为:
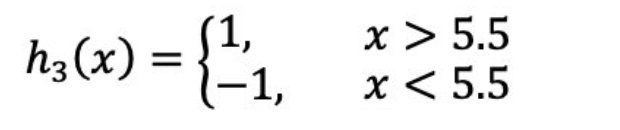
(b)计算该学习器在训练数据中的错误率:
ε3=0.1820
(c)计算该学习器的投票权重:
α3=0.7514
(d)根据投票权重,对训练数据重新赋权:
经计算得,D2的值为:
D4=(0.125,0.125,0.125,0.102,0.102,0.102,0.065,0.065,0.065,0.125)
H3(x)=sign[0.4236h1(x)+0.6496h2(x)+0.7514h3(x)]
分类器H3(x)在训练数据集上的误分类点个数为0。
步骤三:对m个学习器进行加权投票,获取最终分类器
H3(x)=sign[0.4236h1(x)+0.6496h2(x)+0.7514h3(x)]
1.5.4. 4.4 api
- from sklearn.ensemble import AdaBoostClassifier
1.6. 5 小结
- 什么是Boosting 【知道】
- 随着学习的积累从弱到强
- 代表算法:Adaboost,GBDT,XGBoost,LightGBM
- bagging和boosting的区别【知道】
- 区别一:数据方面
- Bagging:对数据进行采样训练;
- Boosting:根据前一轮学习结果调整数据的重要性。
- 区别二:投票方面
- Bagging:所有学习器平权投票;
- Boosting:对学习器进行加权投票。
- 区别三:学习顺序
- Bagging的学习是并行的,每个学习器没有依赖关系;
- Boosting学习是串行,学习有先后顺序。
- 区别四:主要作用
- Bagging主要用于提高泛化性能(解决过拟合,也可以说降低方差)
- Boosting主要用于提高训练精度 (解决欠拟合,也可以说降低偏差)
- AdaBoost构造过程【知道】
- 步骤一:初始化训练数据权重相等,训练第一个学习器;
- 步骤二:AdaBoost反复学习基本分类器;
- 步骤三:对m个学习器进行加权投票